ITF225129 Innføring i operativsystemer
Obligatorisk oppgave 9: Page replacement
I denne obligatoriske oppgaven skal du programmere tre algoritmer for å gjøre page replacement i minnehåndtering. Programmene som du lager skal ta utgangspunkt i kode som er gitt i oppgaven. For mer bakgrunnstoff om minnehåndtering, se læreboken og læringsmodulen i Canvas.
Oppgaveteksten består av to deler:
-
I den første delen gis det en kort innføring i minnehåndtering med virtuelt minne og paging. Her finner du en beskrivelse av de tre algoritmene for page replacement som skal programmeres. Det er også gitt en beskrivelse av C-koden som skal brukes i oppgavene i del 2.
-
Den andre delen inneholder selve programmeringsoppgavene som du skal svare på. Det skal leveres besvarelser i form av filer som inneholder C-kode.
1 Virtuelt minne og algoritmer for page replacement
Datamaskinene våre kjører mange prosesser som har behov for mye minne. Spesielt multimedia-applikasjoner kan kreve flere GB med RAM. Noen av disse prosessene er i seg selv for store til å passe inn i det tilgjengelige minnet. Det samlede minnebehovet til alle prosesser på systemet kan ofte være (mye) større enn det fysiske minnet som er tilgjengelig i user space. Vi trenger derfor å kunne kjøre programmer som bare har deler av minnet sitt liggende i RAM.
Løsninger der hver prosess får ett stort, sammenhengende fysisk minneområde, vil ikke fungere i praksis. Med mange minnekrevende prosesser blir det etter hvert umulig å finne ledige "hull" i minnet som er store nok. Det tar også alt for lang tid å lese/skrive store minneområder til/fra disk når minnet er fullt.
Det er derfor utviklet løsninger som deler opp minnet for en prosess i mindre deler, slik at noen deler kan ligge i RAM og andre midlertidig på disk:
- Virtuelt minne
- Paging
- Segmentering
I denne oppgaven skal vi se nærmere på virtuelt minne og paging.
1.1 Virtuelt minne
For å løse problemet med for lite fysisk minne, bruker vi en abstraksjon som kalles for "virtuelt minne" ("virtual memory"). Kompilatoren som oversetter f.eks. C-koden vår til eksekverbare maskininstruksjoner, adresserer dette "ikke-eksisterende" virtuelle minnet for å lese/skrive data. Det samlede virtuelle minnet er oftest større enn det fysiske minnet som er tilgjengelig i maskinen.
Når en prosess kjører, forholder den seg bare til det virtuelle minnet. Denne løsningen kan litt forenklet beskrives slik:
-
Hver prosess tildeles ett sammenhengende tenkt/virtuelt minneområde – en "array" eller "tabell" med minne som kan indekseres på bytenivå med minneadresser.
-
Laveste minneadresse for prosessen "peker til" starten på denne tenkte arrayen med virtuelt minne. Høyeste minneadresse peker til den siste byten med minne i arrayen.
-
Prosessen skal aksessere bare sitt eget minne. Hvis den prøver å bruke en adresse som er utenfor minneområdet, vil operativsystemet sende et signal til prosessen — en "segmentation fault" — som oftest vil stoppe prosessen med en feilmelding.
-
Operativsystemet og CPU håndterer virtuelle minneadresser og tilordner dem til korrekte adresser i det fysiske primærminnet.
-
CPU jobber sammen med en egen "superrask" maskinvare — Memory Management Unit (MMU) — som gjør automatisk oversettelse fra virtuelle til fysiske minneadresser. Dette er vist på figuren nedenfor;
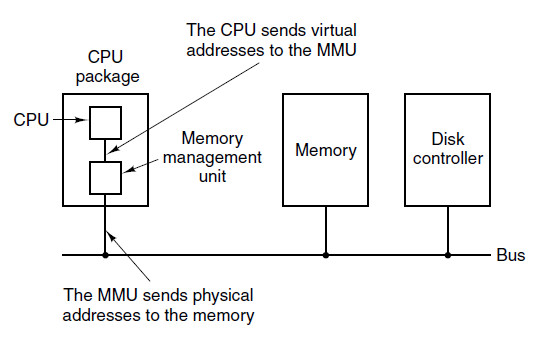
1.2 Paging
Virtuelt minne brukes alltid sammen med en teknikk som kalles for "paging". Dette løser problemene forbundet med store og sammenhengende minneområder. Paging tillater at en prosess har deler av eget minne i RAM, mens andre deler kan være lagret på disk. Det blir også mer effektivt å gjøre "swapping", dvs. å flytte minne mellom RAM og disk, når vi bruker paging.
1.2.1 Pages i det virtuelle minnet
Det virtuelle minneområdet for en prosess deles inn i mindre deler som kalles for "pages". En page er en sammenhengende blokk med virtuelt minne. Vi kan tenke på en page som et sammenhengende område i prosessens "array" med virtuelt minne. Den starter i en gitt indeks og har en lengde som er antall bytes i pagen. Typisk pagestørrelse i et Linux-system er 4kB.
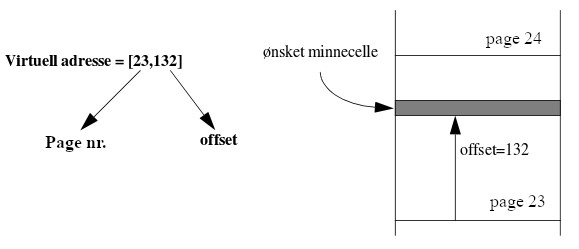
Det virtuelle minnet til prosessen deles opp i pages som nummereres fra page 0 (første page) og videre utover i "minnearrayen". En virtuell minneadresse vil (hvis vi forenkler litt) bestå av to deler:
-
Et "page-nummer", som angir hvor i det virtuelle minnet denne pagen starter.
-
Et "offset" som angir hvor mange bytes det er fra starten av pagen til minnecellen/byten som adresseres.
Figuren nedenfor viser (forenklet) et eksempel på sammenhengen mellom en virtuell minneadresse og det virtuelle minnet:
1.2.2 Fysiske page frames og pagetabeller
Det fysiske primærminnet deles opp i tilsvarende page frames. En page frame er et område av RAM som har samme størrelse som en virtuell page. Hver virtuell page som en prosess bruker vil være lagret i en fysisk page frame. Operativsystemet og CPU'ens minnestyring (med MMU) sørger for at en prosess som adresserer en virtuell page får lest fra/skrevet til riktig page frame.
En page frame kan ligge lagret i RAM, eller den kan være "swappet ut" og ligge lagret på disk. Det betyr at hele eller deler av minnet som en prosess bruker kan ligge utenfor RAM. Det samlede minnebehovet til alle prosessene kan derfor være vesentlig større enn hva det faktisk er plass til i maskinens RAM.
Koblingen mellom virtuelt og fysisk minne for en prosess gjøres med bruk av en pagetabell, som håndteres av den delen av operativsystemet som kalles Memory Manager.
Hvert element i en pagetabell, et page table entry, lagrer informasjon for én virtuell page med prosessminne. Den viktigste informasjonen i et slikt entry er den fysiske adressen til en page frame, der dataene i den virtuelle pagen er lagret fysisk. Vi kan tenke på pagetabell som en funksjon som avbilder virtuelle minneadresser over på fysiske minneadresser.
Figuren nedenfor gir et (svært forenklet) bilde av virkemåten til en pagetabell:
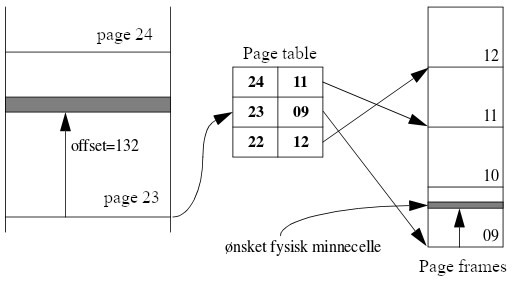
I denne figuren brukes den samme virtuelle minneadressen [23,132] som ble vist i figuren i avsnitt 1.2.1. I pagetabellens indeks 23, som er nummeret på den virtuelle pagen, finner vi verdien 9. Dette er nummeret til en page frame i det fysiske minnet, der dataene i virtuell page 23 faktisk ligger lagret. Den riktige minnecellen i RAM adresseres da ved å legge til offset (132) til page frame adressen. Virtuell og fysisk minnecelle som svarer til hverandre er skravert på figuren.
1.3 Page fault og page replacement
Fordi det samlede virtuelle minnet kan være større enn kapasiteten til RAM, vil innholdet i en page frame enten ligge i RAM eller være swappet ut på disk. Dette håndteres av Memory Manager i OS, som lagrer og vedlikeholder diskadressene til page frames som ikke er i RAM.
Hvis en prosess adresserer en virtuell page som ikke ligger i RAM, får vi et avbrudd som kalles for en page fault. Memory Manager må da sørge for at den riktige page frame leses fra disk og inn i RAM, før prosessen kan fortsette:
Pagen som ble adressert av prosessen leses fra disk inn i en ledig page frame.
Pagetabellen oppdateres slik at den peker til riktig page frame.
Men:
-
Hvis prosessens tildelte minneområde i RAM er fullt når vi får en page fault, må det først frigis plass til dataene som skal leses fra disk.
-
Dette byttet av innholdet i en page frame i RAM kalles for page replacement.
Memory Manager må velge hvilken av prosessens page frames som skal tas ut av RAM og lagres på disk.
Valget av page frame gjøres med en page replacement algoritme.
1.4 Page replacement algoritmer
Fordi diskaksesser er svært tidkrevende i forhold til å lese/skrive i RAM, ønsker vi så få page faults som mulig. Hvis vi bare velger en tilfeldig page for replacement (lagring på disk), vil vi ofte velge mye brukte pages. Disse vil da raskt måtte leses inn igjen, og vi får mye diskbruk og dårlig effektivitet.
Gode page replacement algoritmer prøver å finne lite brukte pages. For å få til dette bruker de bl.a. informasjon som lagres i entries i pagetabellen.
Figuren nedenfor viser noe av innholdet som typisk lagres for hver virtuell page i prosessens pagetabell:
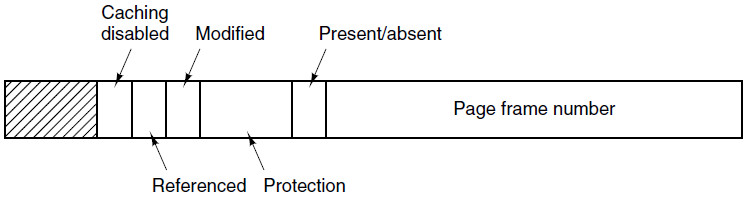
Vi ser at en slik entry bl.a inneholder:
- Page frame number: Hvor i RAM pagen er lagret.
- Present/absent bit: Er pagen er lagret i RAM eller på disk?
- Protection: En beskyttelseskode for lese- og skrivetilgang.
- Caching disabled bit: Kan page frame lagres i CPU-cachen?
I tillegg inneholder et page table entry to statusbits som typisk brukes av page replacement algoritmer:
- Modified:
- Modified bit M vil være lik 1 (true) hvis pagen er skrevet til/endret siden den kom inn i RAM, og 0 (false) ellers.
- Referenced:
- Referenced bit R vil være lik 1 (true) hvis en page nylig er lest fra eller skrevet til, og 0 (false) ellers. R settes automatisk tilbake til 0 for alle pages med jevne mellomrom, f.eks. ved annethvert klokkeavbrudd
Nedenfor er det beskrevet tre relativt enkle algoritmer for page replacement som du skal programmere. En av dem bruker statusbit til å velge hvilken page som skal tas ut av RAM.
Det kan også brukes ytterligere informasjon for å gjøre page replacement. Det er vanlig å lagre tidspunktet når en page ble lagt inn i RAM. I aging-algoritmen som er beskrevet i pensum, lagres det en "R-bit historikk" for å se hvilke pages som er minst brukt "i det siste". Algoritmen LRU (se nedenfor) bruker en liste med tidspunktene for siste lesing/skriving av hver page.
I beskrivelsen av de tre algoritmene nedenfor, og i programmene som du skal skrive, skal vi bruke denne informasjonen om pages:
| # | Load | Last | R | M |
|---|---|---|---|---|
| 0 | 126 | 280 | 1 | 0 |
| 1 | 230 | 265 | 0 | 1 |
| 2 | 140 | 270 | 0 | 0 |
| 3 | 110 | 285 | 1 | 1 |
I tabellen ovenfor er det følgende data, med tidspunkter angitt i "systemtid", for fire pages som vi kan anta ligger i RAM:
- #: Pagenummer, 0, 1, 2, 3, ...
- Load: Tidspunktet ("load time") for når pagen ble lagt inn i RAM
- Last: Tidspunktet for siste referanse ("last reference") til page
- R og M: Verdiene for referenced bit og modified bit.
Spørsmålet som besvares nedenfor for de ulike algoritmene er: Hvilken page vil her bli valgt ut for replacement?
1.4.1 First-In-First-Out
Algoritmen First-In-First-Out (FIFO) er svært enkel: Ved page replacement velges den page som har ligget lengst i RAM. FIFO bruker bare dataene om "ankomst-tid" til RAM.
For eksempelet i tabellen ovenfor vil algoritmen måtte gå gjennom kolonnen "Load", der vi finner tidspunktet for når pagen ble lagt inn i RAM. Den vil da velge page nummer 3 som den page som skal flyttes til disk:
| # | Load |
|---|---|
| 0 | 126 |
| 1 | 230 |
| 2 | 140 |
| 3 | 110 |
I en standard implementering av FIFO-algoritmen ville man brukt en vanlig kø til å lagre pages, for å få den effektiv uten søk etter minste verdi for "Load". Nye pages vil da legges bakerst i kø, og replacement gjøres ved å ta ut første page i køen.
Du skal ikke programmere noen kø i din besvarelse, men bare finne minste verdi for "Load" ved å gå gjennom en array med page-strukturer (se nedenfor).
Merk at FIFO-algoritmen ikke tar hensyn til hvor ofte en page leses/skrives. Den er derfor lite effektiv og brukes ikke i praksis, men er i stedet utgangspunkt for andre og bedre algoritmer for page replacement.
1.4.2 Least Recently Used
Algoritmen Least Recently Used (LRU) er basert på følgende idé: Pages som er mye brukt nylig vil antagelig også bli brukt på nytt om kort tid. LRU-algoritmen tar ut den page i RAM som er minst brukt i den "siste tiden" før page fault skjedde. Effektiviteten til LRU avhenger av hvor langt man "ser bakover", dvs. hvordan man definerer denne "siste tiden".
Det kan bevises at LRU er tilnærmet optimal hvis vi tar vare på alle minneaksesser, vektet med tidspunkt, som gjøres for hver page. Men dette blir for langsomt i praksis, fordi det krever at vi vedlikeholder en sortert liste av alle pages hver gang minnet leses/skrives.
En enkel variant av LRU får vi ved alltid å ta vare på tidspunktet for siste gang en page ble referert til (tiden da den sist ble lest eller skrevet av prosessen). Dette er gjort i tabellen med fire pages som er vist avsnitt 1.4 ovenfor, i kolonnen "Last":
| # | Last |
|---|---|
| 0 | 280 |
| 1 | 265 |
| 2 | 270 |
| 3 | 285 |
Her vil en enkel LRU-algoritme bare gå gjennom tidene for siste referanse. I dette tilfellet velges page 1 ut for replacement, siden den har minst verdi for "Last".
1.4.3 Second Chance
Algoritmen Second Chance ligner på FIFO, men den sjekker også R-bit for å unngå å velge pages som nylig er brukt.
Anta at det skjer en page fault ved (system)tiden T. Second Chance for page replacement kan beskrives slik:
-
Velg den pagen P som er "eldst" (har ligget lengst i RAM):
-
Hvis P ikke har vært referert til (lest/skrevet) "nylig", dvs. at den har referenced bit R=0, velges P for replacement. Algoritmen er da ferdig.
-
Hvis P har vært referert til (lest/skrevet) "nylig", dvs. at den har referenced bit R=1, får pagen en "second chance". Vi setter R=0 og oppdaterer "alderen" til P (tiden den ankom RAM) til å være lik nåværende tid T. Den får altså status i algoritmen som en helt nyankommet page.
-
- Gå til punkt 1 i algoritmen.
Second Chance vil første sjekke "eldste" page, deretter nest eldste osv. Den fungerer mye bedre enn FIFO fordi den vil "kaste ut" pages som har ligget lenge i RAM uten å bli brukt. Algoritmen fungerer som FIFO hvis R=1 for alle pages.
Vi skal se nøyere på Second Chance algoritmen når den kjøres på samme eksempel som ovenfor. Den vil bare trenge å bruke kolonnene for "load time" og referenced bit R:
-
Anta at page fault skjer ved tiden T=300, og at dataene om fire pages da ser slik ut:
# Load R 0 126 1 1 230 0 2 140 0 3 110 1 -
Page 3 velges først fordi den er "eldst". Men siden den har referenced bit lik 1, får den en "second chance". R settes lik 0 og ankomsttiden lik T:
# Load R 0 126 1 1 230 0 2 140 0 3 300 0 -
I neste steg velges page 0, som nå har minste ankomsttid. Den har også referenced bit lik 1, så igjen settes R lik 0 og ankomsttid lik T:
# Load R 0 300 0 1 230 0 2 140 0 3 300 0 -
Page 2 har nå minst ankomsttid. Fordi den har referenced bit lik 0 får den ikke en "second chance", men velges for replacement. Algoritmen er da ferdig:
# Load R 0 300 0 1 230 0 2 140 0 3 300 0
I en standard implementering ville man også her, som for FIFO, brukt en vanlig kø til å lagre pages. Du skal ikke programmere noen kø i din besvarelse, men bare gå gjennom en array med page-strukturer (se nedenfor).
1.5 Simulering av page replacement algoritmer
I oppgavene nedenfor skal du programmere tre C-funksjoner som simulerer/implementerer page replacement algoritmene beskrevet ovenfor. Hver funksjon skal bare skrive ut en linje med informasjon om hvilken page som algoritmen har valgt.
1.5.1 Forenklinger
Vi kan anta at det har oppstått en page fault i en prosess ved systemtiden T. Prosessminnet er fullt og det må gjøres page replacement. Det skal velges ut én page fra et lite antall pages i RAM. Valget skal gjøres med en page replacement algoritme.
1.5.2 Input
Inndataene til programmet er en fil der det ligger informasjon om N pages. Først på filen ligger antall pages N. Deretter kommer det én linje med fem data for hver page. Alle dataene er heltall, og er de samme som er brukt i eksemplet vi har sett ovenfor:
| # | Load | Last | R | M |
|---|---|---|---|---|
| 0 | 126 | 280 | 1 | 0 |
| 1 | 230 | 265 | 0 | 1 |
| 2 | 140 | 270 | 0 | 0 |
| 3 | 110 | 285 | 1 | 1 |
- #: Pagenummer, 0, 1, 2, 3, ...
- Load: Tidspunktet ("load time") for når pagen ble lagt inn i RAM
- Last: Tidspunktet for siste referanse ("last reference") til page
- R og M: Verdiene for referenced bit og modified bit.
Datafilen for dette eksemplet vil se slik ut:
4
0 126 280 1 0
1 230 265 0 1
2 140 270 0 0
3 110 285 1 1Det er gitt en funksjon read_file() i koden nedenfor som leser inn pagedataene fra fil. Du vil altså ikke trenge å programmere dette selv.
1.5.3 Datastruktur for page frames
Dataene for hver page frame skal lagres i en struct page_frame. En slik struktur skal inneholde de fem heltallsverdiene for pagen som leses inn fra fil.
Alle de N pagene skal lagres i en array PF med page-frame-strukturer. Arrayen PF skal deklareres globalt i programmet, utenfor funksjonene og main(), slik at den er tilgjengelig i all koden. Det samme gjelder for antall pages, N, og systemtiden T.
1.5.4 C-kode som skal brukes i oppgavene
Nedenfor er det gitt ufullstendig kode for et C-program som simulerer page replacement med tre ulike algoritmer. Du skal bruke denne koden som utgangspunkt for din egen besvarelse på oppgavene i del 2. Koden kan gjerne skrives om og formateres anderledes.
Strukturen struct page_frame og arrayen PF med page frames er allerede lagt inn i koden, sammen med de globale variablene N og T. Systemtiden T er gitt en verdi som passer med testdataene som skal leses inn. Det er også gitt en funksjon read_file() som oppretter arrayen PF og leser alle page frames inn fra fil.
Hovedprogrammet main() leser et filnavn fra bruker og kaller read_file() for å lese pagedataene. Deretter utføres det tre kall på funksjoner som simulerer page replacement med hver sin algoritme. Du skal programmere disse tre funksjonene.
Se kommentarene i koden nedenfor for en nærmere forklaring av variabler og hva programmet skal utføre.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// Struktur som lagrer data om en page frame
struct page_frame
{
int id; // Page-ID/-number
int load; // Tidspunkt da pagen ble lagt inn i RAM
int last; // Tidspunkt da pagen siste ble referert til
int R; // Referenced bit
int M; // Modified bit
};
// Globale variabler
int T = 300; // Systemtid, settes til passende verdi
int N; // Antall prosesser
struct page_frame *PF; // Peker til array med page frames
// read_file(): Leser data for N page frames fra fil. Pages skal
// ligge sortert på ankomsttid. Alle data må være ikke-negative
// heltall. Alle tider oppgis i hele tidsenheter. Filformat:
//
// N
// id load last R M
// id load last R M
// id load last R M
// ...
//
void read_file(char *filename)
{
int i;
FILE *p_file;
// Åpner fil og sjekker for feil i åpning
p_file = fopen(filename, "r");
if (p_file == NULL)
{
printf("Feil ved åpning av filen \"%s\"\n", filename);
exit(-1);
}
// Leser antall page frames
fscanf(p_file, "%d", &N);
// Oppretter array med plass til alle pages
PF = (struct page_frame *) malloc(N * sizeof(struct page_frame));
// Leser inn en og en page frame.
for (i = 0; i < N; i++)
fscanf(p_file, "%d %d %d %d %d", &PF[i].id, &PF[i].load,
&PF[i].last, &PF[i].R, &PF[i].M);
fclose(p_file);
}
//first_in_first_out(): Simulering av page replacement med FIFO
//
void first_in_first_out()
{
// Skal programmeres ferdig i oppgave 1
}
//least_recently_used(): Simulering av page replacement med LRU
//
void least_recently_used()
{
// Skal programmeres ferdig i oppgave 2
}
//second_chance(): Simulering av page replacement med Second Chance
//
void second_chance()
{
// Skal programmeres ferdig i oppgave 3
}
// main(): Leser filnavn med page frame data, leser inndata fra fil og
// kjører tre ulike page replacement algoritmer
//
int main()
{
char filename[100];
// Leser filnavn fra bruker
printf("File? ");
scanf("%s", filename);
// Leser inn prosessdataene
read_file(filename);
// Simulerer page replacement
first_in_first_out();
least_recently_used();
second_chance();
}2 Oppgaver
Det er gitt tre (forhåpentligvis) enkle oppgaver som skal besvares med C-kode. For å teste programmene dine kan du bruke disse to datafilene som input:
Oppgave 1
Programmer ferdig funksjonen first_in_first_out() i koden gitt ovenfor, slik at den implementerer FIFO-algoritmen for page replacement. Funksjonen skal gå gjennom de innleste pagedataene og skrive ut hvilken page som velges for replacement. For eksemplet med fire pages gitt i avsnitt 1.4 ovenfor (og på filen T0.txt), skal utskriften se slik ut:
First-In-First-Out
Page: 3 Loaded: 110 Last ref: 285 R: 1 M: 1Oppgave 2
Programmer ferdig funksjonen least_recently_used() i koden gitt ovenfor, slik at den implementerer LRU-algoritmen for page replacement. Funksjonen skal gå gjennom de innleste pagedataene og skrive ut hvilken page som velges for replacement. For eksemplet med fire pages gitt i avsnitt 1.4 ovenfor (og på filen T0.txt), skal utskriften se slik ut:
Least Recently Used
Page: 1 Loaded: 230 Last ref: 265 R: 0 M: 1Oppgave 3
Programmer ferdig funksjonen second_chance() i koden gitt ovenfor, slik at den implementerer algoritmen Second Chance for page replacement. Funksjonen skal gå gjennom de innleste pagedataene og skrive ut hvilken page som velges for replacement. For eksemplet med fire pages gitt i avsnitt 1.4 ovenfor (og på filen T0.txt), skal utskriften se slik ut:
Second Chance
Page: 2 Loaded: 140 Last ref: 270 R: 0 M: 0Hva skal du levere?
Svarene på oppgave 1, 2 og 3 skal legges inn i en og samme fil med navn oblig_9.c. C-filen skal lastes opp i Canvas.